




Plugin Information
| Version | 2.1.0 |
|---|---|
| Author | Dataiku (Hicham EL BOUKKOURI) |
| Released | 2018-09 |
| Last updated | 2023-04 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
⚠️ You do not need this plugin for RAG purposes, nor for having text features in VisualML
This plugin provides a tool for computing numerical sentence representations (also known as Sentence Embeddings).
These embeddings can be used as features to train a downstream machine learning model (for sentiment analysis for example). They can also be used to compare texts and compute their similarity using distance or similarity metrics.
These embeddings cannot be used for RAG purposes. See the docs about RAG for more information.
Since Dataiku DSS 10.0.4, Visual Machine Learning provides Sentence Embedding text preprocessing to create features for training machine learning models. The Visual ML integration offers more models and is thus recommended instead of this plugin for modelling. However, it does not yet allow to measure distances between different embeddings or get embeddings in a dataset like this plugin. See the docs about feature handling in Dataiku for more information.
Note that this plugin does currently not support containerized execution.
Features
This plugin comes with:
- A macro that allows you to download pre-trained word embeddings from various models: Word2vec, GloVe, FastText or ELMo.
- A recipe that allows you to use these vectors to compute sentence embeddings. This recipe relies on one of two possible aggregation methods:
- Simple Average: Averages the word embeddings of a text to get its sentence embedding.
- SIF embedding: Computes a weighted average of word embeddings, followed by the removal of their first principal component. For more information about SIF, you can refer to this paper or this blogpost.
- A second recipe that allows you to compute the distance between texts. It first computes text representations like in the previous recipe. Then it computes their distances using one of the following metrics:
- Cosine Distance: Computes
1 - cos(x, y)wherexandyare the sentences’ word vectors. - Euclidean Distance: Equivalent to
L2distance between two vectors. - Absolute Distance: Equivalent to
L1distance between two vectors. - Earth-Mover Distance: Informally, the minimum cost of turning one word vector into the other. For more details refer to the following Wikipedia article.
- Cosine Distance: Computes
Macro
Download pre-trained embeddings
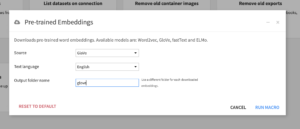
This macro downloads the specified model’s pre-trained embeddings (Source) into the specified managed folder (Output folder name) of the flow. If the folder doesn’t exist, it will be auto-created.
Available models:
- Word2vec (English)
- GloVe (English)
- FastText (English & French, selectable via Text language)
- ELMo (English)
Note: Unlike the other models, ELMo produces contextualized word embeddings. This means that the model will process the sentence where a word occurs to produce a context-dependent representation. As a result, ELMo embeddings are better but also slower to compute.
Recipes
Input
Sentence Embeddings can be computed based on an input dataset with text data.
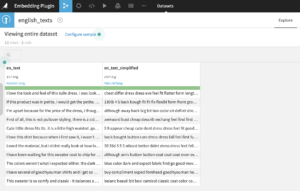
Recipe Selection
If the recipe has been installed you can select and add it to the flow.
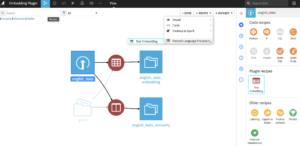
Compute sentence embeddings: Parameters
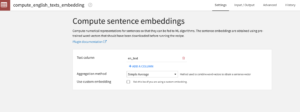
This recipe creates sentence embeddings for the texts of a given column. The sentence embeddings are obtained using pre-trained word embeddings and one of the following two aggregation methods: a simple average aggregation (by default) or a weighted aggregation (so-called SIF embeddings).
How to use the recipe
Select the downloaded pre-trained word embeddings, your dataset with the column(s) containing your texts, an aggregation method and run the recipe!
Note: For SIF embeddings you can set advanced hyper-parameters such as the model’s smoothing parameter and the number of components to extract.
Note: You can also use your own custom word embeddings. To do that, you will need to create a managed folder and put the embeddings in a text file where each line corresponds to a different word embedding in the following format: word emb1 emb2 emb3 ... embN where emb are the embedding values. For example, if the word dataiku has a word vector [0.2, 1.2, 1, -0.6] then its corresponding line in the text file should be: dataiku 0.2 1.2 1 -0.6.
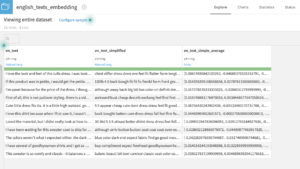
Compute sentence embeddings: Output
Compute sentence similarity: Parameters
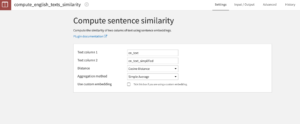
This recipe takes two text columns and computes their distance. The distance is based on sentence vectors computed using pre-trained word embeddings that are compared using one of three available metrics: cosine distance (default), euclidian distance (L2), absolute distance (L1) or earth-mover distance.
How to use the recipe
Using this recipe is similar to using the “Compute sentence embeddings” recipe. The only differences are that you will now choose exactly two text columns and you will have the option to choose a distance metric from the list of available distances.
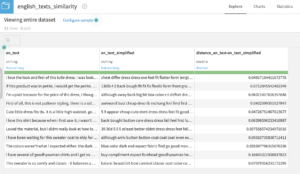
Compute sentence similarity: Output
References
- SIF references:
Sanjeev Arora, Yingyu Liang and Tengyu Ma, A Simple but Tough-to-Beat Baseline for Sentence Embeddings
- Word2vec references:
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013.
- GloVe references:
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.
- FastText references:
P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information
- ELMo references:
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner,
Christopher Clark, Kenton Lee, Luke Zettlemoyer. Deep contextualized word representations NAACL 2018.