




Plugin Information
| Version | 0.0.4 |
|---|---|
| Author | Dataiku |
| Released | 2021-12 |
| Last updated | 2023-04 |
| License | Apache-2.0 |
| Source code | Github |
| Reporting issues | Github |
This plugin provides a set of tools to create a recommendation system workflow and predict future user-item interactions. It is composed of:
- A set of recipes to compute collaborative filtering and generate negative samples:
- Auto collaborative filtering: Compute collaborative filtering scores from a dataset of user-item samples
- Custom collaborative filtering: Compute affinity scores from a dataset of user-item samples and a dataset of similarity scores (i.e similarity between pairs of users or items)
- Sampling: Generate negative samples from user-item implicit feedbacks (that necessary includes only positive samples)
- A pre-packaged recommendation system workflow in a Dataiku Application, so you can create your first recommendation system in a few clicks.
Table of contents
How to set up
Right after installing the plugin, you will need to build its code environment. If this is the first time you install this plugin, click on Build new environment.
Note that Python version 3.6 or 3.7 is required.
Connections
The plugin recipes run on SQL databases. Both the input and outputs datasets of the recipes must be in the same SQL connection.
Supported SQL connections: PostgreSQL, Snowflake, Google BigQuery, Microsoft SQL Server, Azure Synapse.
How to use
The plugin provides 3 recipes that can be used together to build a complete recommendation flow in DSS.
You can also generate a first recommendation system in a a few clicks thanks to the Dataiku Application.
Auto collaborative filtering
Use this recipe to compute collaborative filtering scores from a dataset of user-item samples. Optionally, you can provide explicit feedbacks (a rating is associated to each interaction between a user and an item) that will be taken into account to compute affinity scores.
Summary
In this recipe, some user-item samples are first filtered based on some pre-processing parameters (users or items with not enough interactions and old interactions are filtered).
Then, depending on whether you chose user-based or item-based collaborative filtering, similarity scores between users (or items) are computed.
- For user-based, the similarity between user 1 and user 2 is based on the number of same items user 1 and user 2 have interacted with
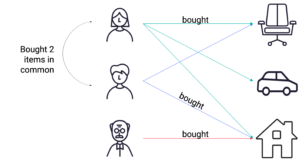
- For item-based, the similarity between item 1 and item 2 is based of the number of users that interacted both with item 1 and item 2
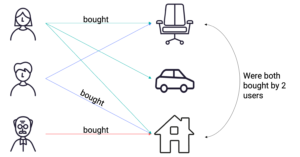
Finally, using the similarity matrix generated before, we compute the affinity score between a user and an item using the user’s top N most similar users that have interacted with the item.
Notes:
- In case of explicit feedbacks (if a rating column is provided):
- The similarity between users is computed using the Pearson correlation.
- The affinity score between a user u and an item i is computed by taking the weighted average of the ratings of the top N users that are most similar to user u who rated item i.
- All of the above is for user-based collaborative filtering, the item-based approach is symmetrical.
Input
-
Samples dataset with user-item pairs (one column for the items, another column for the users) and optionally a timestamp column and a numerical explicit feedback column.
Output
-
Scored samples dataset of new user-item pairs (not in the input dataset) with affinity scores.
- (Optional) Similarity scores dataset of either users or items similarity scores used to compute the affinity scores.
Settings
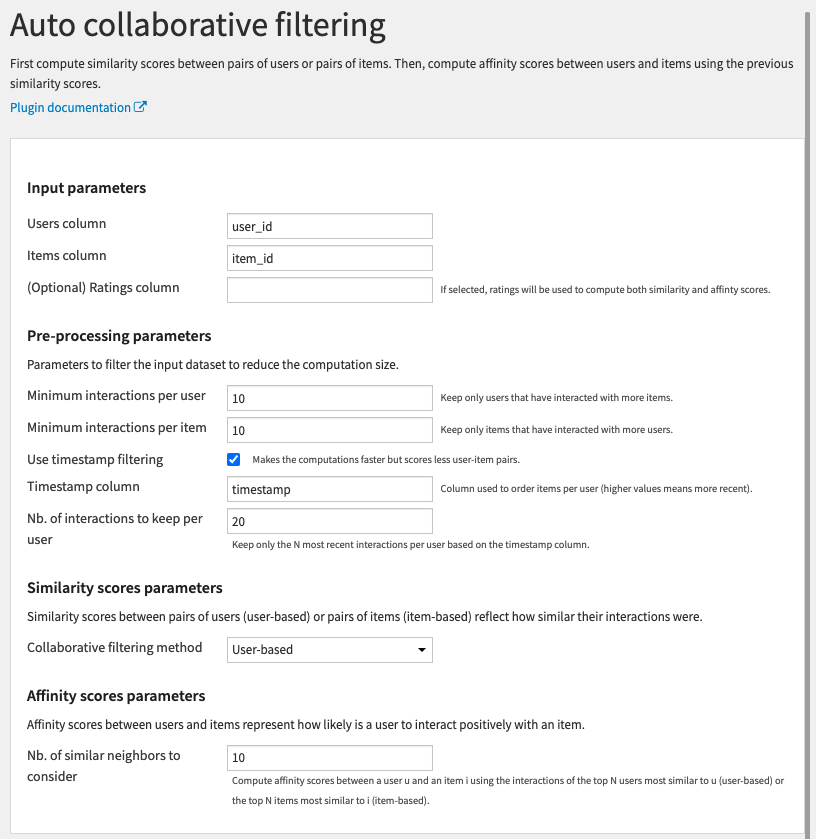
Input parameters
- Users column: Column with users id
- Items column: Column with items id
- (Optional) Ratings column: Column with numerical explicit feedbacks (such as ratings)
- If not specified, the recipe will use implicit feedbacks.
- In explicit feedbacks, the Pearson correlation is used to compute similarity between either users or items.
Pre-processing parameters
- Minimum visits per user: Users that have interacted with less items are removed
- Minimum visits per item: Items that have interacted with less users are removed
- Normalisation method: Choose between
- L1 normalisation: To normalise user-item visits using the L1 norm
- L2 normalisation: To normalise user-item visits using the L2 norm
- Use timestamp filtering: Whether to filter interactions based on a timestamp column
- Timestamp column: Column used to order interactions (can be dates or numerical, higher values means more recent)
- Nb. of items to keep per user: Only the N most recent items seen per user are kept based on the timestamp column
-
Collaborative filtering method: Choose between
- User-based: Compute user-based collaborative filtering scores
- Item-based: Compute item-based collaborative filtering scores
- Nb. of most similar users/items: Compute user-item affinity scores using the N most similar users (in case of user-based) or items (in case of item-based)
Performance
During the score computation, the longest task is to compute the similarity matrix between users or user-based (resp. items for item-based).
To do so, it computes a table of size:
number of users X average number of visit per user X average number of visit per item
(resp. number of items X average number of visit per user X average number of visit per item)
Reducing these metrics will decrease the memory usage and running time.
Custom collaborative filtering
Use this recipe to compute collaborative filtering scores from a dataset of user-item samples and your own similarity scores between users or items.
Summary
This recipe uses the same formula as the Auto collaborative filtering recipe except that it doesn’t compute the similarity scores between users (or items). Instead, you provide these similarity scores yourself. You may have obtained them using some content-based approach.
Input
-
Samples dataset with user-item pairs and optionally a timestamp column and a numerical explicit feedback column.
- Similarity scores dataset of user-user or item-item similarity scores (two columns for the items/users and one column containing scores).
Output
-
Scored samples dataset of new user-item pairs with collaborative filtering scores.
Settings
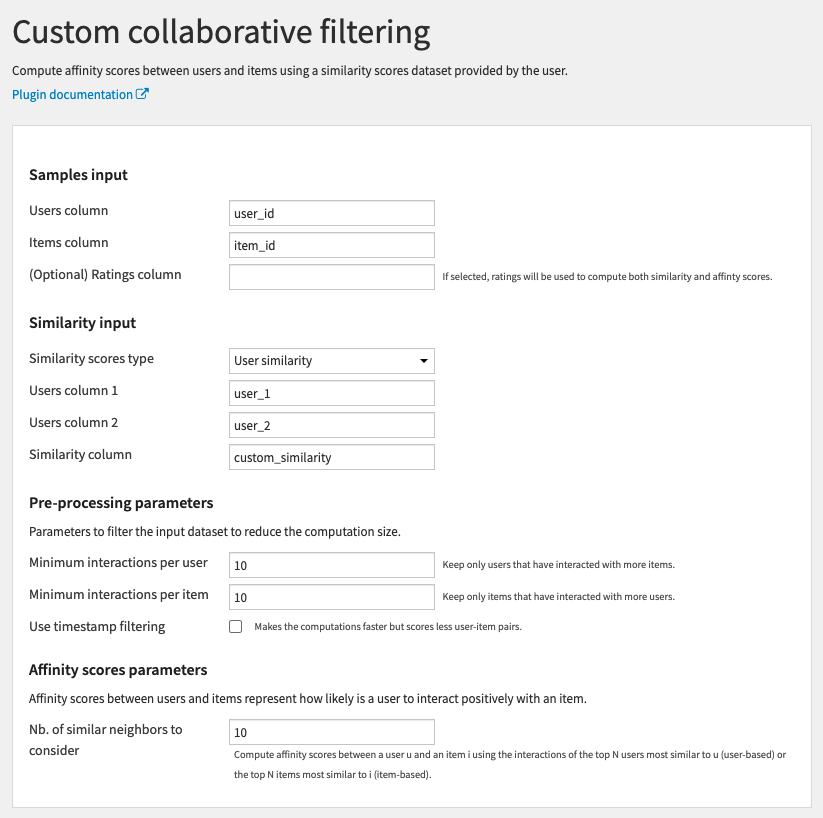
All parameters are the same as in the Auto collaborative filtering recipe except for the Similarity input section.
Similarity input
- Similarity scores type: Choose between
- User similarity: If the input Similarity scores dataset contains users similarity
- Item similarity: If the input Similarity scores dataset contains items similarity
- Users/items column 1: First column with users/items id
- Users/items column 2: Second column with users/items id
- Similarity column: Column with the similarity scores between the users or items
Sampling
Use this recipe to create positive and negative samples from positive user-item samples and scored user-item samples.

Summary
In the case of implicit feedbacks, you only have positive samples (positive interactions between users and items).
In order to build a model that uses the affinity scores (computed using the previous recipes) as features and predicts if a user is likely to interact with an item or not, you need negative samples (user-item pairs that didn’t interact).
This recipe generates negative samples that have affinity scores but are not positive samples.
Input
-
Scored samples dataset of user-item samples with one or more affinity scores.
- Training samples dataset of user-item positive samples.
- (Optional) Historical samples dataset of historical user-item samples used to compute the affinity scores.
Output
- Positive and negative scored samples dataset of user-item positive and negative samples with affinity scores.
Settings
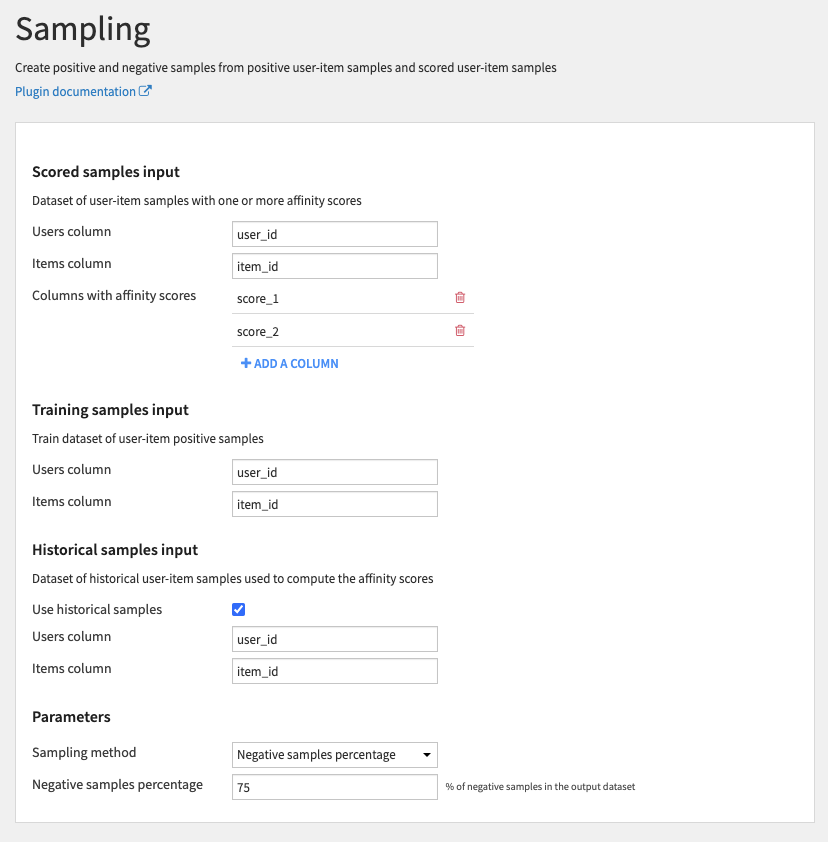
Scored samples input
- Users column: Column with users id
- Items column: Column with items id
- Columns with affinity scores: Columns with scores obtained from the collaborative filtering recipes
Training samples input
- Users column: Column with users id
- Items column: Column with items id
Historical samples input
- Use historical samples: Whether to use the historical samples to remove them from the negative samples
- Users column: Column with users id
- Items column: Column with items id
Parameters
- Sampling method: Choose between
-
No sampling: Generate all possible negative samples (all user-item pairs not in the training samples dataset)
-
Negative samples percentage: Generate negative samples to obtain a fixed ratio of positive/negative samples per users
-
- Negative samples percentage: Percentage of negative samples per users to generate
Pre-packaged Recommendation System workflow
Summary
Alongside the recipes, a Dataiku application is provided in the plugin. This application can be used to create a first basic recommendation workflow in SQL using the plugin recipes. Once the flow is instantiated through the application, it becomes easier to customize it by adding more features, algorithms and affinity scores.
The complete flow can be integrated into a production project that evaluates the recommendations.
It accepts as input a dataset of dated interactions between users and items (with users, items and timestamp columns).
The system will base its recommendations on implicit feedbacks (no ratings are used).
Once the recommendation model is trained, an additional dataset of users (with a users column) can be provided and a dataset of the top items to recommend to each user will be built.
The input datasets must be stored in a PostgreSQL or Snowflake connection and all computation will be done in the selected connection.
To get a better understanding of the workflow generated by the Dataiku Application, you can look at the project wiki. You can also find more details here.
Settings
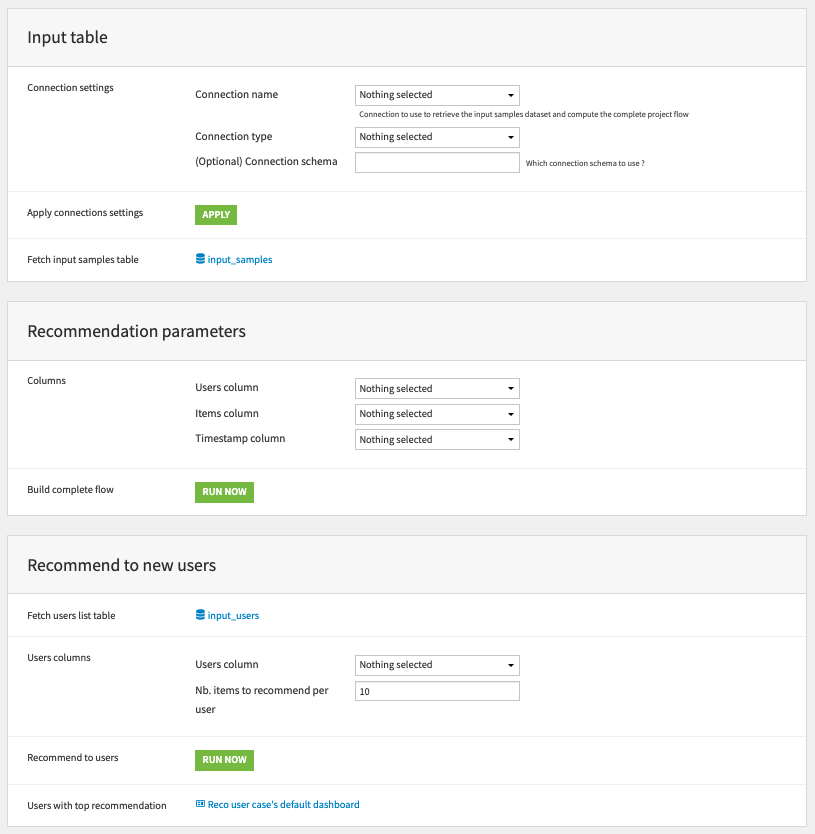
Input table
- Connection settings: Select settings of the SQL connection to be used in the flow
- Connection name: Name of the SQL connection to use (SQL connections must be set by an admin user of DSS)
- Connection type: Type of the SQL connection (the application supports PostgreSQL and Snowflake)
- (Optional) Connection schema: Schema of the selected SQL database to use (can be left empty)
- Apply connection settings: Run this scenario to change all datasets connection in the flow to the selected connection
- Fetch input samples table: This links redirects to the settings of the input dataset of the flow (see next image). There you can fetch your input table by first clicking on the Get tables list button. Once the SQL table is selected, you can test it (with the Test table button) and save it (the blue Save button) before going back to the application parameters page.
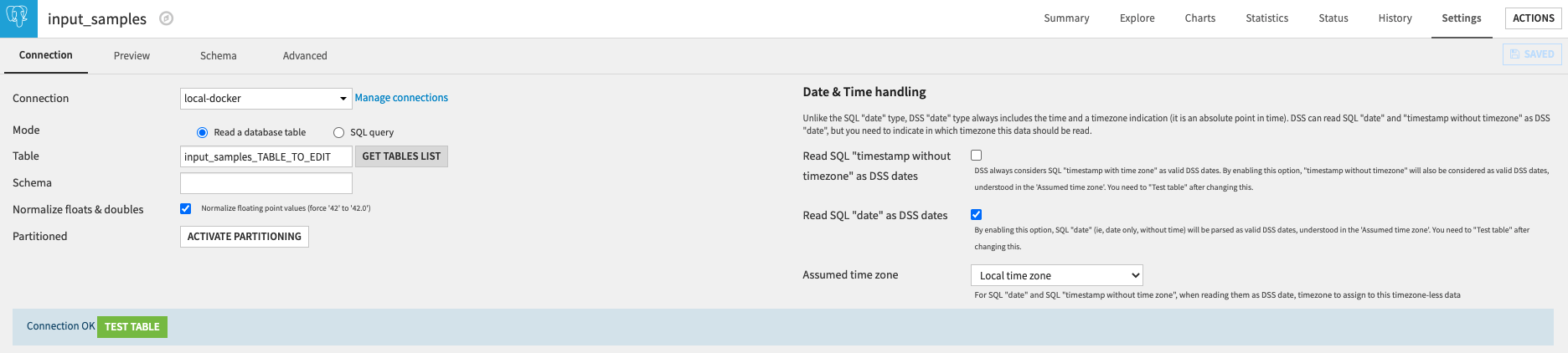
Recommendation parameters
- Columns: Select required columns from the fetched input table
- Users column: Column with users id
- Items column: Column with items id
- Timestamp column: Column with timestamps (or dates)
- Build complete flow: Run this scenario to build all datasets of the complete recommendation flow
Recommend to new users
- Fetch users list table: Like for the input samples tables, use this links to fetch a SQL table containing a column of users id to make recommendations
- Users columns:
- Users column: Column with users id
- Nb. items to recommend per user: How many items to recommend to each of the input users. Some users may not have any items recommendations.
- Recommend to users: Run this scenario to compute a new dataset containing the selected users top recommendations
- Users with top recommendation: This links redirects to a dashboard showing the dataset containing the top items recommendation per user
Example of a recommendation flow
In this section, we explain how the 3 recipes can be used to build a complete recommendation flow. The same flow is used in the Dataiku application.
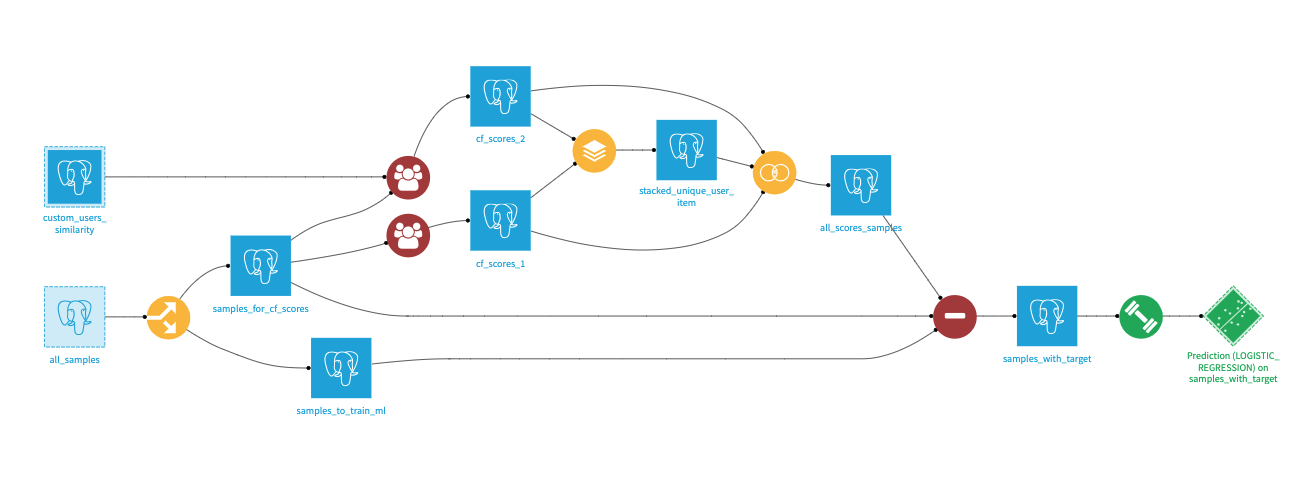
Intro
Before going into details, let’s first take an overview of what a recommendation system could look like in DSS. The goal of the workflow is to predict whether a user is likely to interact with an item, based on a set of historical interactions. The predictions can be computed using the Dataiku Machine Learning capabilities, but you’ll still need to build predictive features. For that we will use the collaborative filtering recipe to compute a set of affinity scores. These different affinity scores will be joined in a single dataset and serve as the input features of the machine learning model.
Time-based split
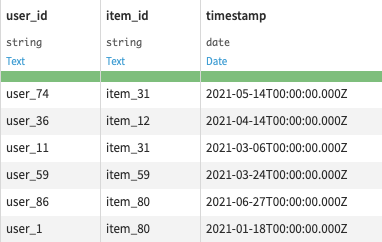
First we split the all_samples dataset of user-item interactions based on the timestamp to get 2 datasets of old and recent interactions:
- samples_for_cf_scores: old interactions used to compute scores between users and items
- samples_to_train_ml: recent interactions used to get positive samples to train a ML model on the affinity scores
It’s important to train the ML model with more recent interactions than the ones used to compute the affinity scores to prevent data leakage. In production, all interactions are used to compute affinity scores and new samples are scored by the model.
Collaborative filtering scores
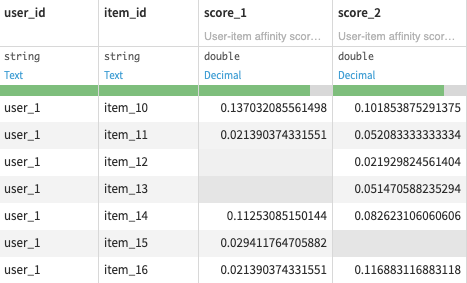
Then we compute multiple affinity scores using the samples_for_cf_scores dataset of interactions and the collaborative filtering recipes.
We can also provide our own users (or items) similarity datasets as input of the Custom collaborative filtering recipe (here the custom_users_similarity dataset).
The multiple scores are joined together into the all_scores_samples dataset (first a stack recipe with distinct rows to retrieve all user-items pairs then a full join recipe to get the multiple scores).
Sampling
We have computed affinity scores for user-item pairs. Some of these pairs are interactions present in the samples_to_train_ml, they are positive samples, others did not interact together and are negative samples (not present in the samples_to_train_ml or samples_for_cf_scores datasets).
The Sampling recipe takes as inputs the samples_for_cf_scores, samples_to_train_ml and all_scores_samples datasets and outputs the scored pairs with a target column indicating whether they are positive or negative samples (the ratio of positive and negative samples per users can be fixed with a recipe parameter).
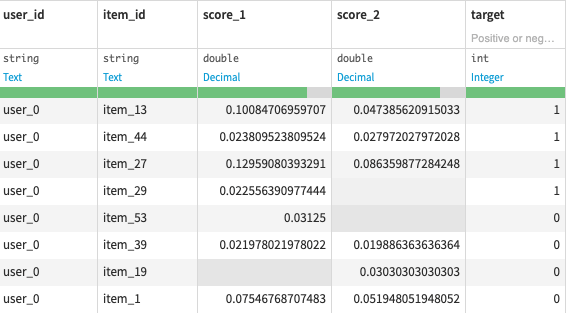
The samples_with_target output dataset can finally be used to train a Machine Learning model to predict the target column using the score columns as features.
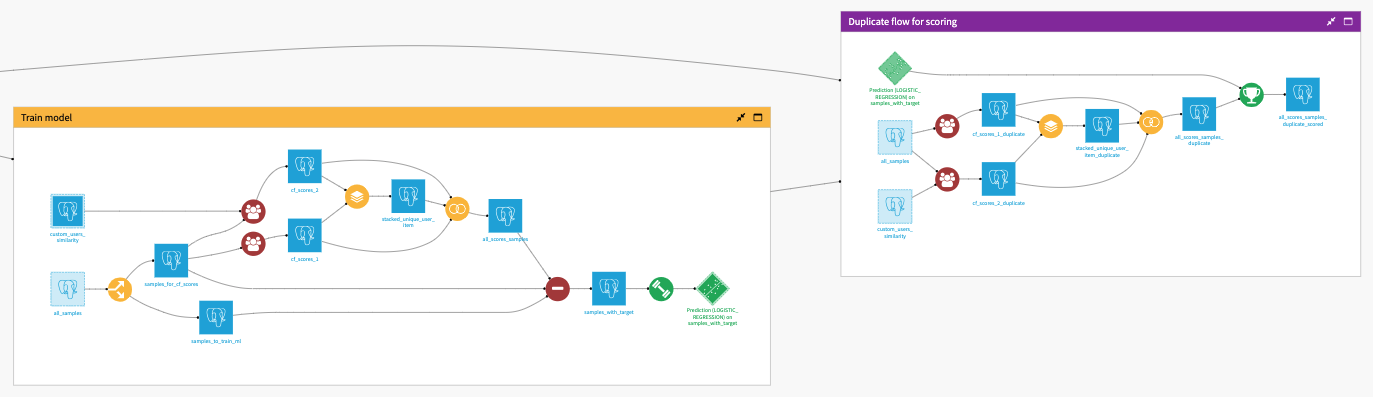
Duplicated flow for scoring
Once the ML model is trained, it can be used in production to predict samples with affinity scores obtained from all past interactions (before the time-based split used to train the model).
To compute the affinity scores used to train a model, only a subset of the interactions was used. Some interactions were left aside to have positive samples in the training.
In production, all past interactions are used to compute the samples affinity scores. The trained model then predicts these scored samples and the predictions are used to make recommendations.
To compute affinity scores using all past interactions, we need to duplicate the collaborative filtering recipes (with the same parameters), make them use the all_samples dataset as input and again join all the computed scores to get the all_scores_samples_duplicate dataset.
Finally, we can predict all samples that have affinity scores by scoring the all_scores_samples_duplicate dataset with the trained model
Dataiku application
To help users build a recommendation system faster, the complete flow explained above is packaged into a Dataiku application.