




Plugin information
| Version | 1.1.1 |
|---|---|
| Author | Dataiku (Niklas MUENNIGHOFF, Mehdi HAMOUMI, Krishna VADAKATTU) |
| Released | 2021-12 |
| Last updated | 2023-07 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
This plugin offers text translation at no charge between 100 languages entirely locally. It uses the open-source M2M100 model. This plugin is only compatible with versions DSS 10 and above.
How to use
Let us assume that you have installed this plugin and that you have a Dataiku DSS project with a dataset containing a column of text to translate. You can optionally have a column indicating the source language, for multiple input languages translation.
Input
- Dataset with a text column to translate and an optional source language column
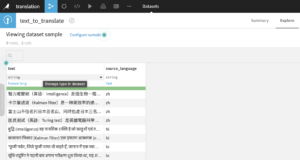
Offline Translation recipe
To create your first recipe, navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin in the right panel.

Settings
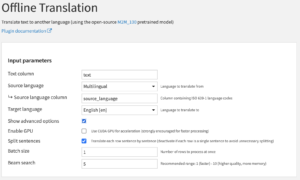
- Review INPUT parameters
- The Text column parameter is the column in the input dataset that you wish to translate.
- The Source language parameter is the original language of the Text column. If you would like to use multiple source languages select Multilingual.
- The Source language column parameter can only be used if Source language is selected as Multilingual. The selected column must contain valid ISO 639-1 language codes for the source language of the corresponding row. The codes must be part of the available languages for the model, hence be part of the Source language dropdown or be listed here.
- The Target language parameter is the language you would like to translate to.
- Selecting Show advanced options will reveal the following additional parameters:
- The Enable GPU parameter will accelerate processing if a GPU is available. If ticked without a GPU, execution will fail.
- The Split sentences parameter sets whether the translation engine should first split the input into sentences. This is enabled by default. If you have one sentence per row, it is advisable to disable it in order to prevent the engine from splitting the sentence unintentionally.
- The Batch size parameter determines how many rows are processed at once. Increasing it from its default of 1 will accelerate execution, but will require more memory. If you do not have enough memory available, increasing this parameter may lead the execution to fail.
- The Beam search parameter controls how many paths the model explores for translation. Increasing this parameter will lead to marginally better performance while slowing execution and requiring more memory. Decreasing this parameter to 1 will increase speed roughly four-fold at the cost of quality.
Output
- Dataset with text translated to another language
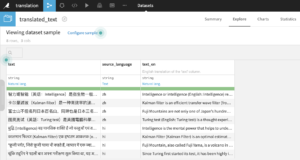
The columns of the output dataset are as follows:
- [Input dataset columns]
- All columns from the input dataset will be preserved
- [selected column]_{target iso code}
- The selected column in its translated version
Happy natural language processing!