




Plugin information
| Version | 1.0.0 |
|---|---|
| Author | Dataiku (Niklas MUENNIGHOFF, Mehdi HAMOUMI, Nicolas DALSASS) |
| Released | 2021-12 |
| Last updated | 2021-12 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
⚠️ This plugin is considered as “deprecated”, we recommend using the OpenAI GPT plugin.
Description
This plugin lets you perform tasks expressed in natural language using Natural Language Generation (NLG) models, either without input data, e.g. “Cities with more than 5 millions inhabitants”, or with input data, e.g. “Match the city to the country it’s in”.
The plugin currently relies on the GPT-3 model from OpenAI. Note that the OpenAI API is a paid service. Check their API pricing page for more information.
How to set up
If you are a Dataiku admin user, follow these configuration steps right after you install the plugin. If you are not an admin, you can forward this to your admin and scroll down to the How to use section.
1. Create an OpenAI account & get your OpenAI API Key
In order to use this plugin you need to setup an account on OpenAI’s website and request API access. You will need the API Key in Dataiku DSS.
2. Create an API configuration preset – in Dataiku DSS
In Dataiku DSS, navigate to the Plugin page > Settings > API configuration and create your first preset.
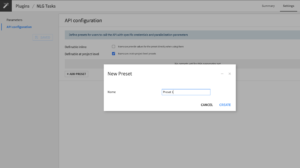
3. Configure the preset – in Dataiku DSS
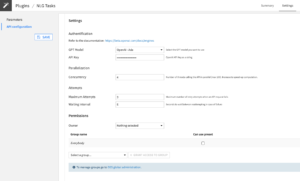
- Fill the AUTHENTICATION settings
- Select the OpenAI engine to use for this configuration
- Copy-paste your OpenAI API key in the corresponding field.
- (Optional) Review the PARALLELIZATION and ATTEMPTS settings
- The default Concurrency parameter means that 4 threads will call the API in parallel.
- We do not recommend changing this default parameter unless your server has a much higher number of CPU cores.
- The Maximum Attempts means that if an API request fails it will be reattempted (default 3 reattempts).
- Regardless of whether the request fails because of e.g. an access error with your OpenAI account or a throttling exception due to too many concurrent requests, it will be tried again.
- The Waiting Interval specifies how long to wait before retrying a failed attempt (default 5 seconds).
- In case of a throttling exception due to too many requests increasing the Waiting Interval may help, however, we recommend first decreasing the Concurrency setting.
- The default Concurrency parameter means that 4 threads will call the API in parallel.
- Set the Permissions of your preset
- You can declare yourself as the Owner of this preset and make it available to everybody, or to a specific group of users.
- Any user belonging to one of those groups on your Dataiku DSS instance will be able to see and use this preset.
Voilà! Your preset is ready to be used.
Configuring additional presets can be useful to segment plugin usage by user group. For instance, you can create a “Default” preset for everyone and a “High performance” one for your Marketing team, with separate billing for each team.
How to use
NLG Tasks recipe
To create your first recipe, navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu.
This plugin can be used to perform tasks with or without referencing input rows.
1. Generate without input rows
When generating without input rows, no input dataset needs to be selected.
Settings
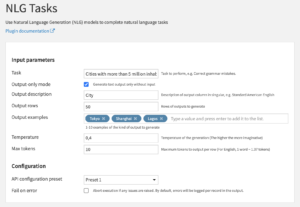
- Review INPUT parameters
- The Task parameter is the task you want the model to perform. Refer to OpenAI’s API reference for example tasks the models can perform.
- The Output-only mode parameter should be activated, when you want to generate without any input. See the generating with input section for an example with input dataset.
- The Output description parameter should be a short natural language description of each expected output row.
- The Output rows parameter corresponds to how many rows you wish to generate.
- The Output examples field should be filled with several examples of the kind of outputs you would like the model to generate. The more examples, the better the performance. However, more examples will send more tokens per request incurring more charges by OpenAI.
- The Temperature parameter controls the imagination of the model. It can be between 0 and 1. Try a lower value for factual generations or a higher one for more creative outputs.
- The Max tokens parameter determines the maximum tokens the model will generate per row. As OpenAI charges based on the number of tokens, lowering this value can help control costs.
Refer to OpenAI’s API reference for additional explanations on the parameters.
- Review CONFIGURATION parameters
- The Preset parameter is automatically filled by the default one made available by your Dataiku admin. You may select another one if multiple presets have been created.
- The Fail on error parameter lets you choose if the recipe should abort execution if any issues are raised. If unchecked, any errors will be logged in two additional columns in the output.
Output
- Dataset with generated text
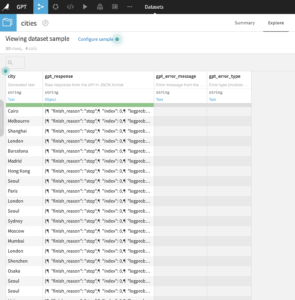
The columns of the output dataset are as follows:
- [Input dataset columns]
- All columns from the optional input dataset will be preserved
- [Output description set in the recipe parameters]
- The generation of the GPT model
- If no output description has been set, this column will be named generation
- gpt_response
- Raw API response in JSON form
- gpt_error_message
- The error message in case an error occurred
- Only present if Fail on error is not selected during configuration
- gpt_error_type
- The error type in case an error occurred
- Only present if Fail on error is not selected during configuration
- gpt_error_message
- The error message in case an error occurred
- Only present if Fail on error is not selected during configuration
2. Generate with input rows
Generating based on input rows requires an input dataset with text data. This example uses the output dataset from the generating without input section and its city column.
Settings
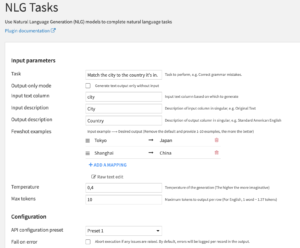
Review INPUT parameters
- The Output-only mode parameter should not be set when you want to generate based on an input dataset.
- The Input text column parameter is the column in the input dataset based on which you want to generate.
- The Input description parameter should be a short natural language description of each incoming row in the Input text column.
- The Fewshot examples field should be filled with several examples of the kind of input-output pairs you expect. The more examples, the better the performance. However, more examples will send more tokens per request incurring more charges by OpenAI.
Refer to the generating without input section for an explanation of the other parameters.
Output
- Dataset with generated text based on an input column
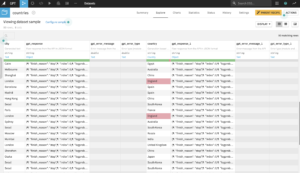
Refer to the generating without input section for an explanation of the output columns.
Happy natural language processing!