





Plugin information
| Version | 1.2.1 |
|---|---|
| Author | Dataiku (Alex COMBESSIE, Joachim ZENTICI) |
| Released | 2020-05 |
| Last updated | 2023-04 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
With this plugin, you will be able to:
- Analyze the sentiment polarity of a text
- Recognize “real-world objects” (people, places, products, companies, etc.) in a text
- Classify text into 700+ predefined content categories
Note that the Google Cloud Natural Language API is a paid service. You can consult the API pricing page to evaluate the future cost.
How to set up
If you are a Dataiku admin user, follow these configuration steps right after you install the plugin. If you are not an admin, you can forward this to your admin and scroll down to the How to use section.
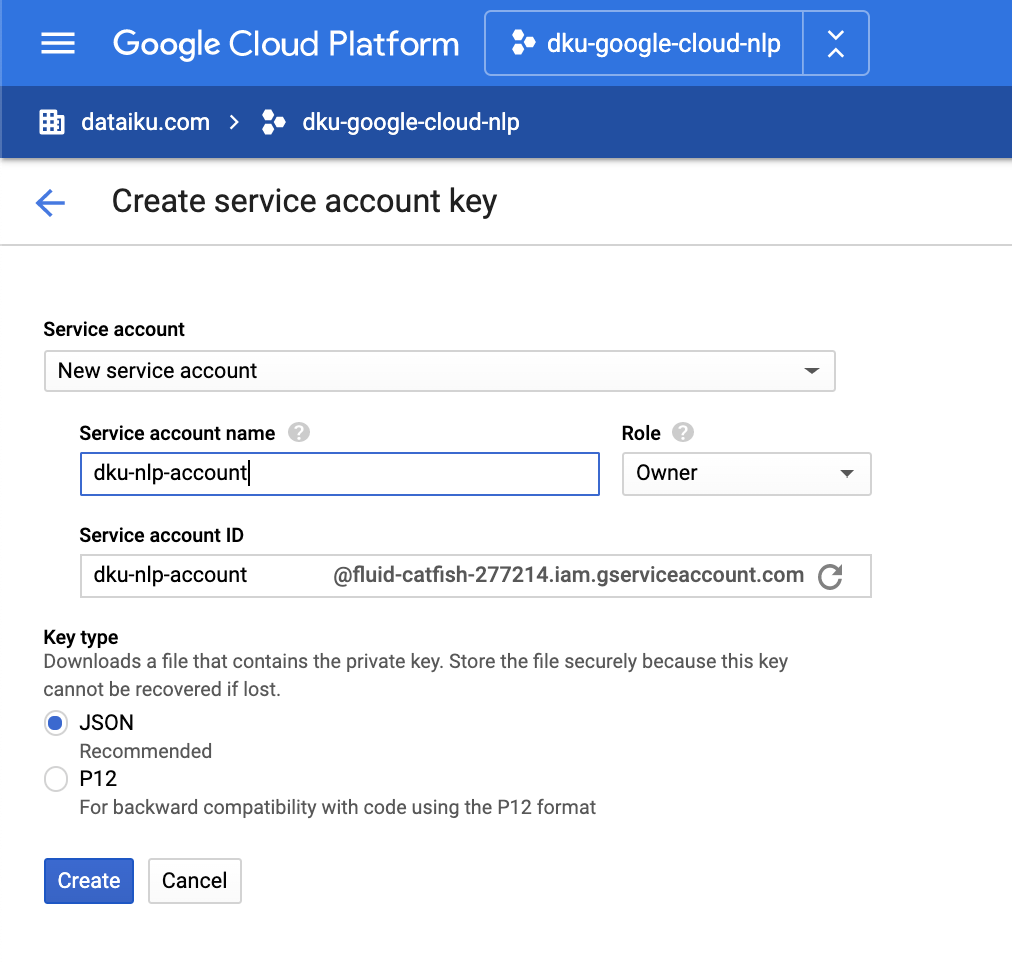
1. Get a service account key for the Natural Language API – in Google Cloud Console
You can follow the step-by-step instructions on this Google Cloud documentation page. Make sure that billing is activated on your Google Cloud project.
Once you complete the “Create a service account and download the private key file” step, you will receive your service account key as a JSON file.
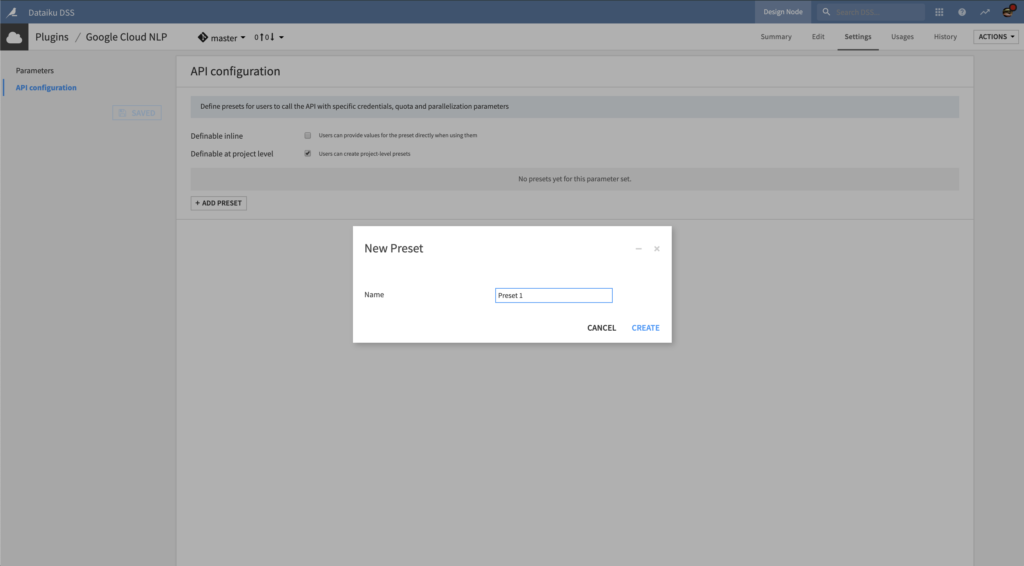
2. Create an API configuration preset – in Dataiku DSS
In Dataiku DSS, navigate to the Plugin page > Settings > API configuration and create your first preset.
3. Configure the preset – in Dataiku DSS
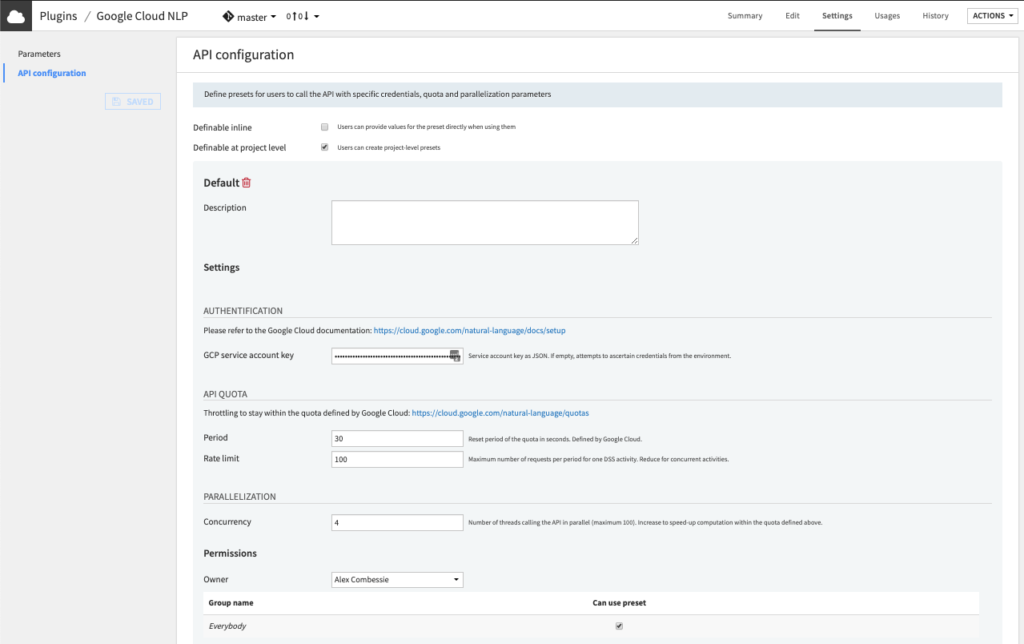
- Fill the AUTHENTIFICATION settings.
- Copy-paste the content of your service account key from Step 1 in the GCP service account key field. Make sure the key is valid JSON.
- Alternatively, you may leave the field empty so that the key is ascertained from the server environment. If you choose this option, please follow this documentation.
- (Optional) Review the API QUOTA settings.
- The default API Quota settings ensure that one recipe calling the API will be throttled at 600 requests (Rate limit parameter) per minute (Period parameter).
- In other words, after sending 600 requests, it will wait for 60 seconds, then send another 600, etc. This default quota is defined by Google. You can request a quota increase, as documented on this page.
- If your quota is already at its maximum and if you envision that multiple recipes will run concurrently to call the API, you may need to decrease the Rate limit parameter. For instance, if you want to allow 10 concurrent DSS activities then you can set this parameter at 600/10 = 60.
- (Optional) Review the PARALLELIZATION settings.
- Set the Permissions of your preset.
- You can declare yourself as Owner of this preset and make it available to everybody, or to a specific group of users.
- Any user belonging to one of these groups on your Dataiku DSS instance will be able to see and use this preset.
Voilà! Your preset is ready to be used.
Later, you (or another Dataiku admin) will be able to add more presets. This can be useful to segment plugin usage by user group. For instance, you can create a “Default” preset for everyone and a “High performance” one for your Marketing team, with separate billing for each team.
How to use
Let’s assume that you have a Dataiku DSS project with a dataset containing text data. This text data must be stored in a dataset, inside a text column, with one row for each document.
As an example, we will use Twitter data from the @elonmusk account. You can follow the same steps with your own data.
To create your first recipe, navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin on the right panel.
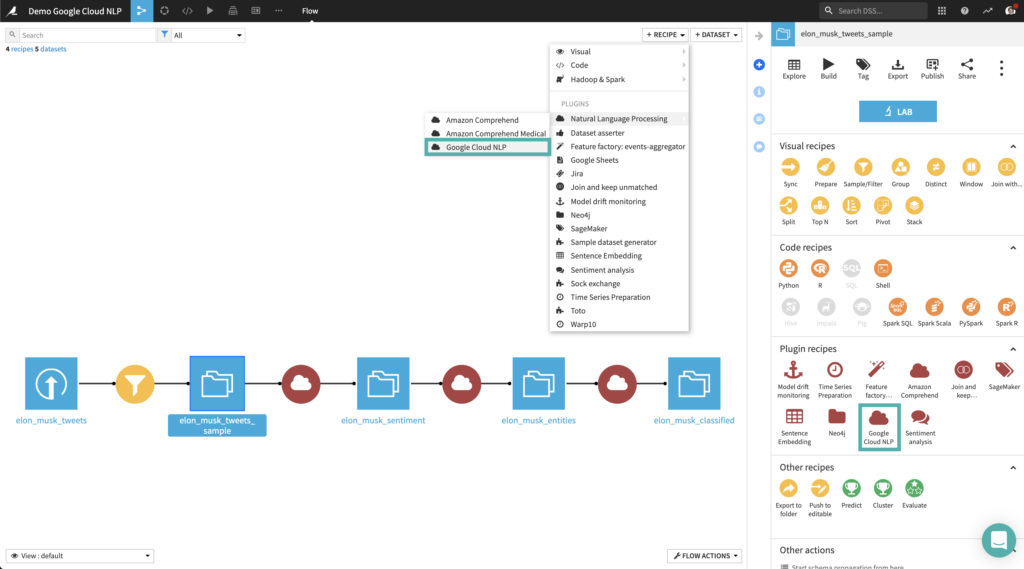
Sentiment Analysis
Input
- Dataset with a text column
Output
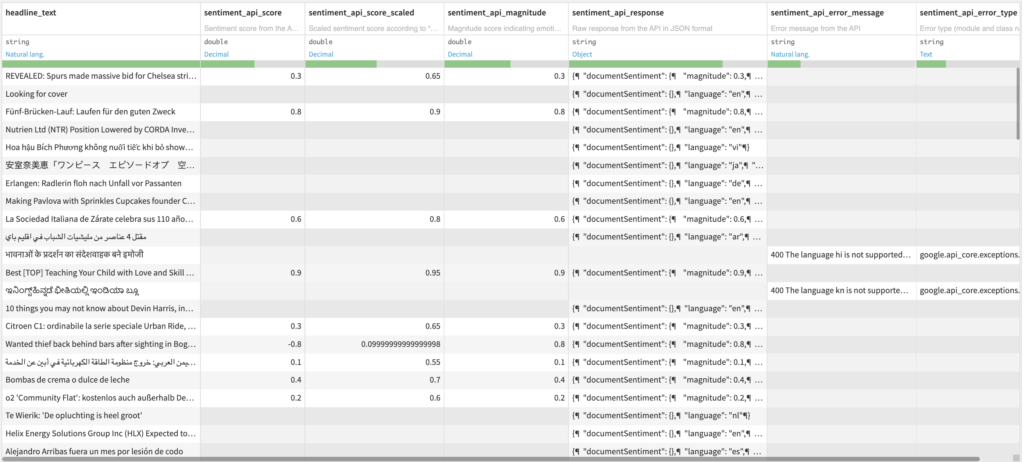
- Dataset with 6 additional columns
- Sentiment score from the API in numerical format between -1 and 1
- Scaled sentiment score according to Sentiment scale parameter
- Magnitude score indicating emotion strength (both positive and negative) between 0 and +Inf
- Raw response from the API in JSON format
- Error message from the API if any
- Error type (module and class name) if any
Settings
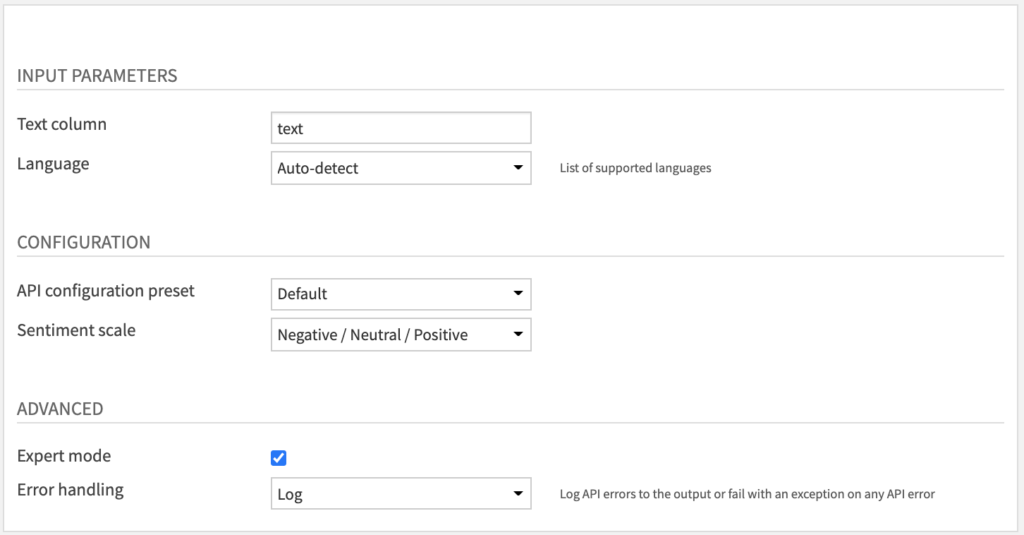
- Fill INPUT PARAMETERS.
- The Text column parameter is for your column containing text data.
- By default, we specify the Language of this column as English.
- You can change it to any of the supported languages listed here or choose “Auto-detect” if you have multiple languages.
- Review CONFIGURATION parameters
- The API configuration preset parameter is automatically filled by the default one made available by your Dataiku admin.
- You may select another one if multiple presets have been created.
- The Sentiment scale parameter allows you to tune the type of categorical or numerical scaling which is applied to the sentiment score from the API.
- In all cases, you will get the raw sentiment score from -1 to 1 and an additional “magnitude” score from 0 to +∞ indicating the strength of emotion.
- The API configuration preset parameter is automatically filled by the default one made available by your Dataiku admin.
- (Optional) Review ADVANCED parameters
- You can activate the Expert mode to access advanced parameters
- The Error handling parameter determines how the recipe will behave if the API returns an error.
- In “Log” error handling, this error will be logged to the output but it will not cause the recipe to fail.
- We do not recommend to change this parameter to “Fail” mode unless this is the desired behaviour.
Named Entity Recognition
Input
- Dataset with a text column
Output
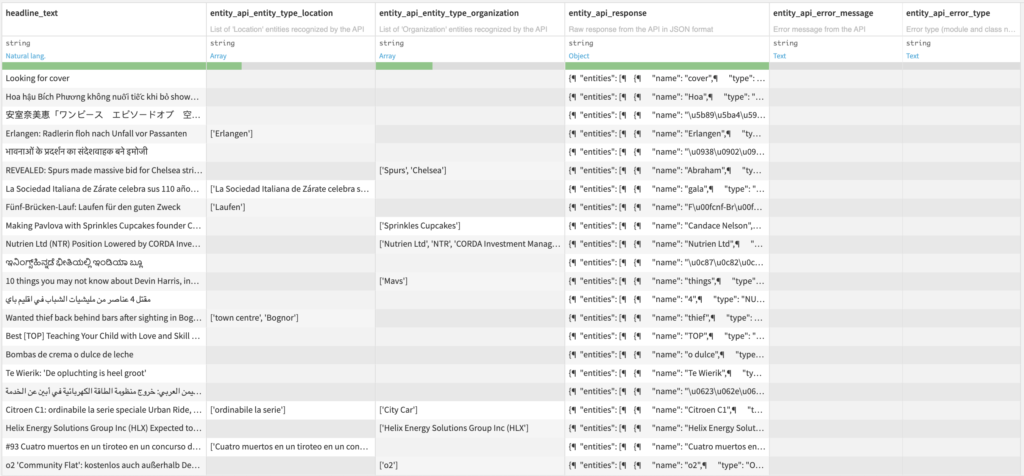
- Dataset with additional columns
- One column for each selected entity type, with a list of entities
- Raw response from the API in JSON format
- Error message from the API if any
- Error type (module and class name) if any
Settings
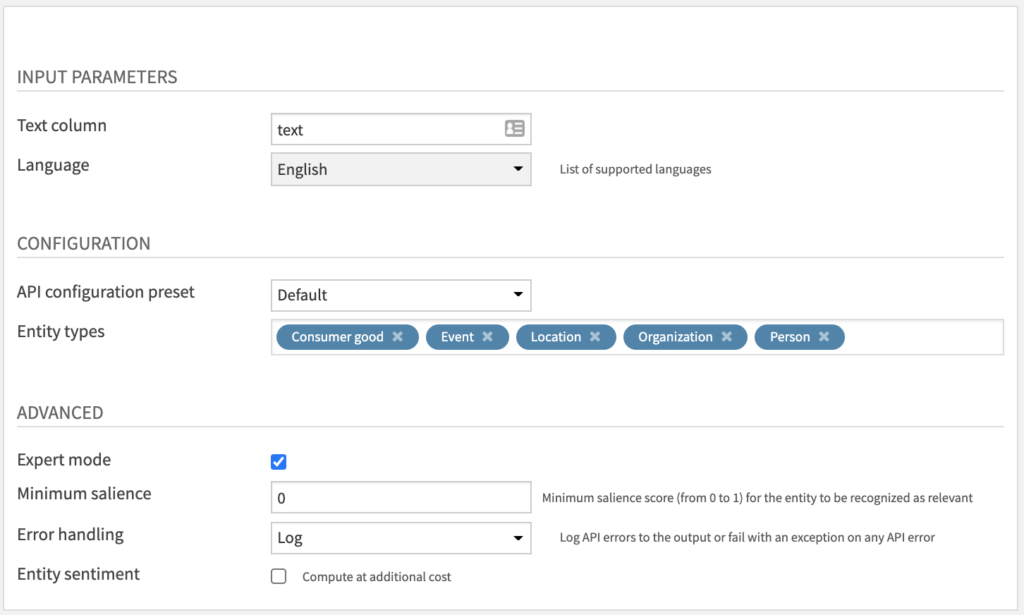
The parameters under INPUT PARAMETERS and CONFIGURATION are almost the same as the Sentiment Analysis recipe (see above). The one addition is:
- Entity types parameter: select multiple among this list
Under ADVANCED with Expert mode activated, you have access to additional parameters which are specific to this recipe:
- Minimum salience: increase from 0 to 1 to filter results which are not relevant. Default is 0 so that no filtering is applied.
- Entity sentiment: activate it to estimate sentiment for each entity. This may increase cost according to the API pricing page.
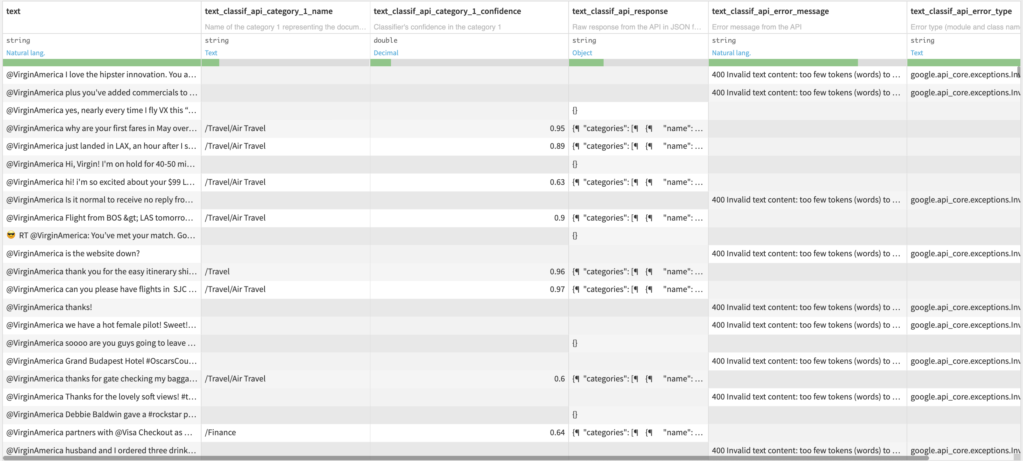
Text Classification
Input
- Dataset with a text column
Output
- Dataset with additional columns
- Two columns for each content category ordered by confidence (see Number of categories parameter)
- Name of the content category, among this list
- Classifier’s confidence in the category
- Raw response from the API in JSON format
- Error message from the API if any
- Error type (module and class name) if any
- Two columns for each content category ordered by confidence (see Number of categories parameter)
Settings
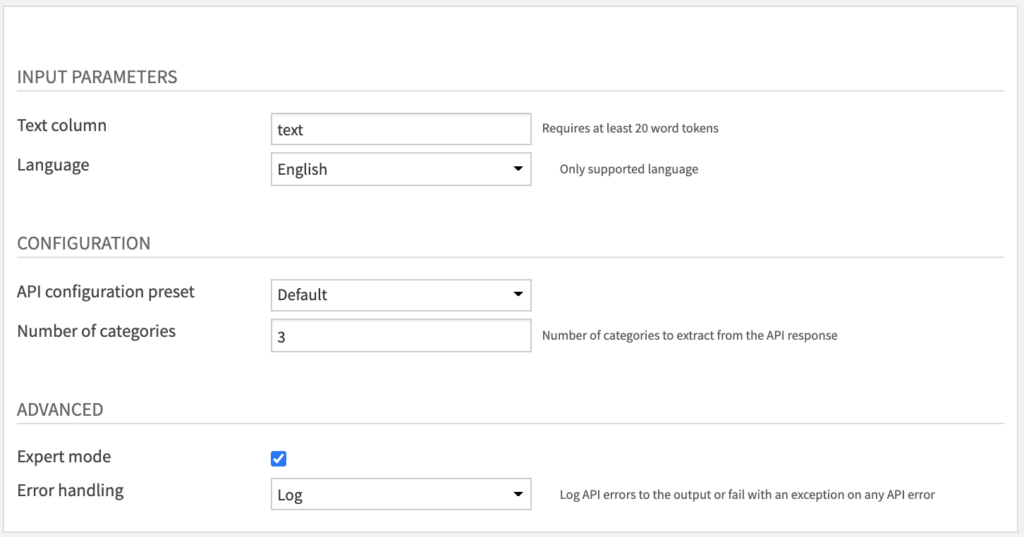
The parameters under INPUT PARAMETERS and CONFIGURATION are almost the same as the Sentiment Analysis recipe (see above). The one addition is:
- Number of categories parameter: how many categories to extract by decreasing order of confidence score. The default value extracts the Top 3 categories from the API results.
Note that only English is supported by the Google NLP API for text classification (as of October 2020).
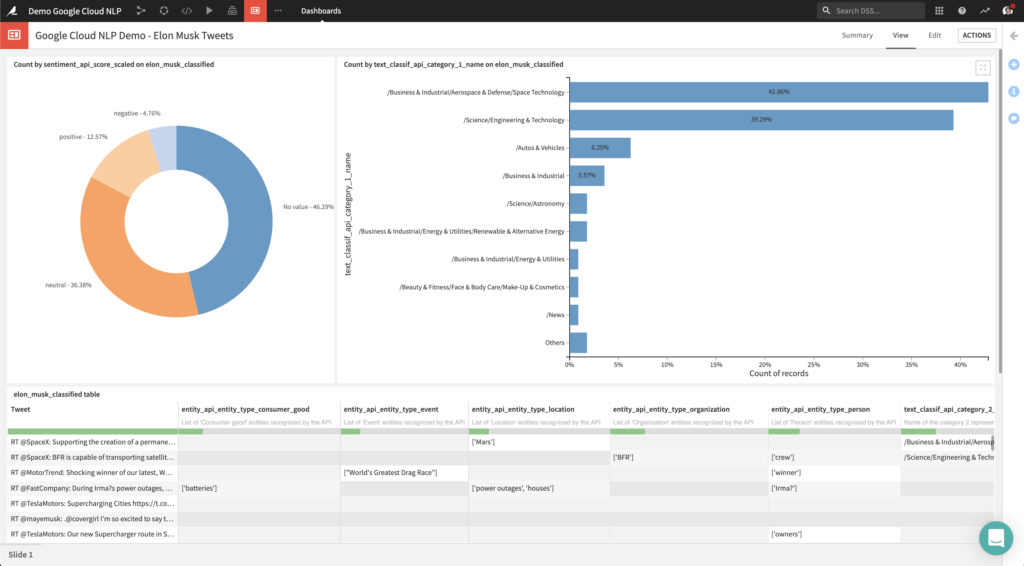
Putting It All Together: Visualization
Thanks to the output datasets produced by the plugin, you can create charts to analyze results from the API. For instance, you can:
- analyze the distribution of sentiment scores
- identify which entities are mentioned
- understand what are the top categories
After crafting these charts, you can share them with business users in a dashboard such as the one below:
Happy natural language processing!