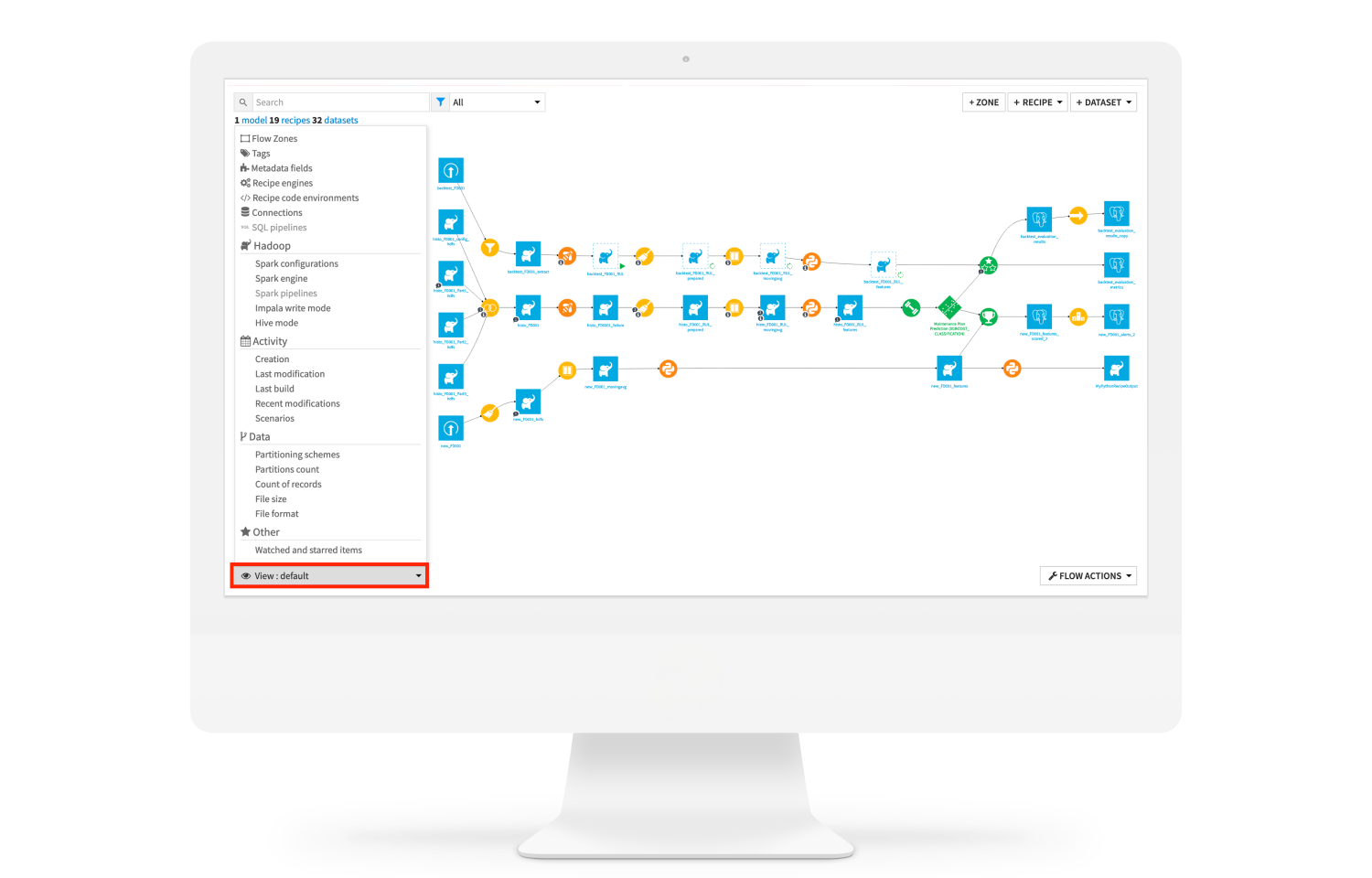
Visualize & Manage Data Pipelines With the Flow
The Dataiku Flow provides a visual representation of data pipelines, making it easy for users to design, understand, and manage complex workflows. Each step in the Flow represents a data operation, from ingestion to transformation and preparation.
Easily alter the Flow with smart controls (e.g., insert recipe, delete and reconnect). With clear control of the pipeline, teams can quickly handle issues and optimize processes for greater efficiency.
Learn About the Dataiku Flow