
信頼性の高い展開を確保する
リアルタイム、バッチのどちらのユースケースに対応するモデルでも、さまざまなインフラストラクチャーや環境にデプロイし、管理することができます。
API経由でリアルタイム予測を提供するモデルだろうと、スケジュールに基づくバッチ処理で稼働するモデルだろうと、Dataikuでは安定した運用維持のための詳細な設定が可能で、スムーズにデプロイできます。
Dataikuでのモデルデプロイについて読む
リアルタイム、バッチのどちらのユースケースに対応するモデルでも、さまざまなインフラストラクチャーや環境にデプロイし、管理することができます。
API経由でリアルタイム予測を提供するモデルだろうと、スケジュールに基づくバッチ処理で稼働するモデルだろうと、Dataikuでは安定した運用維持のための詳細な設定が可能で、スムーズにデプロイできます。
Dataikuでのモデルデプロイについて読む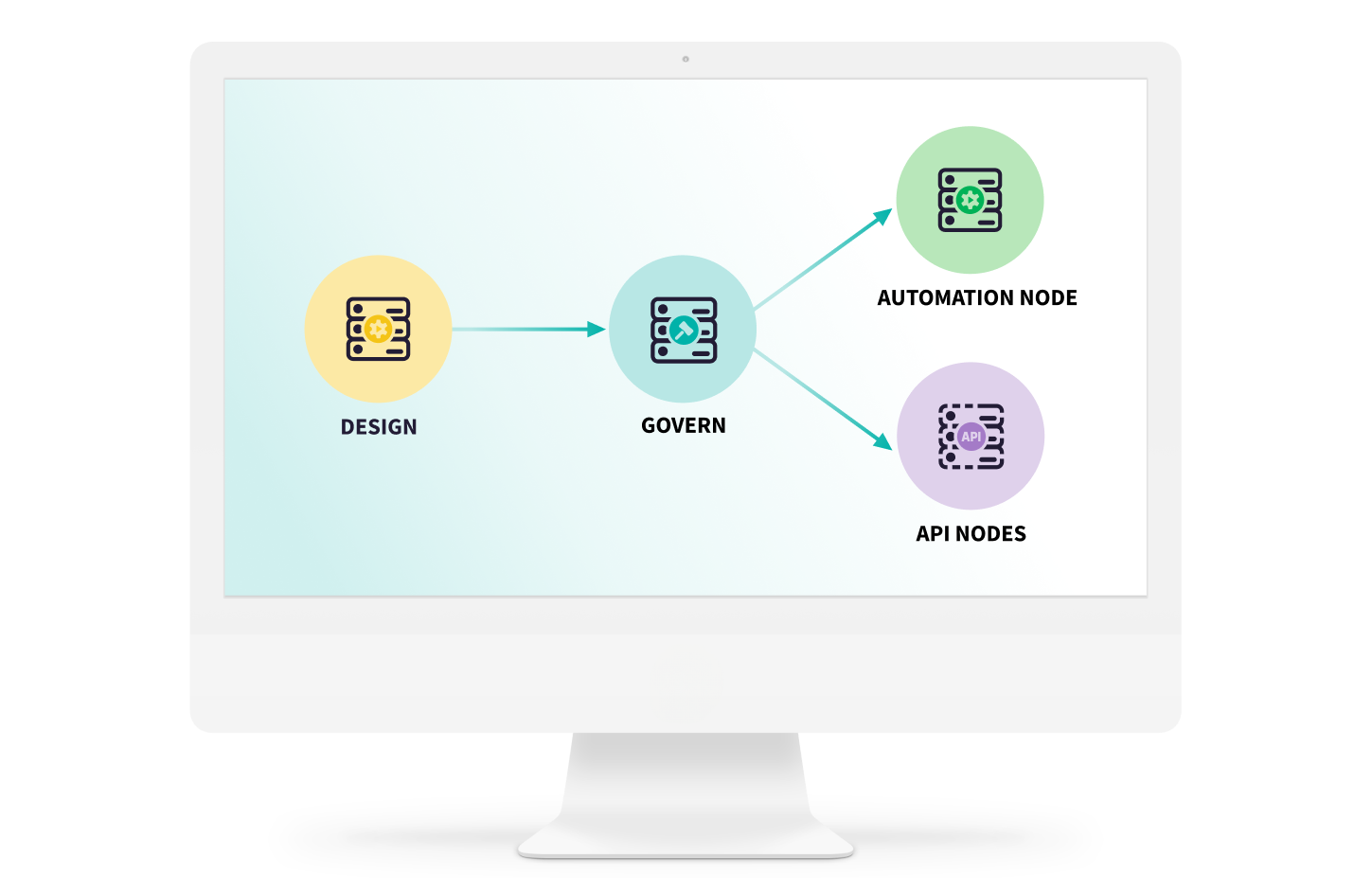
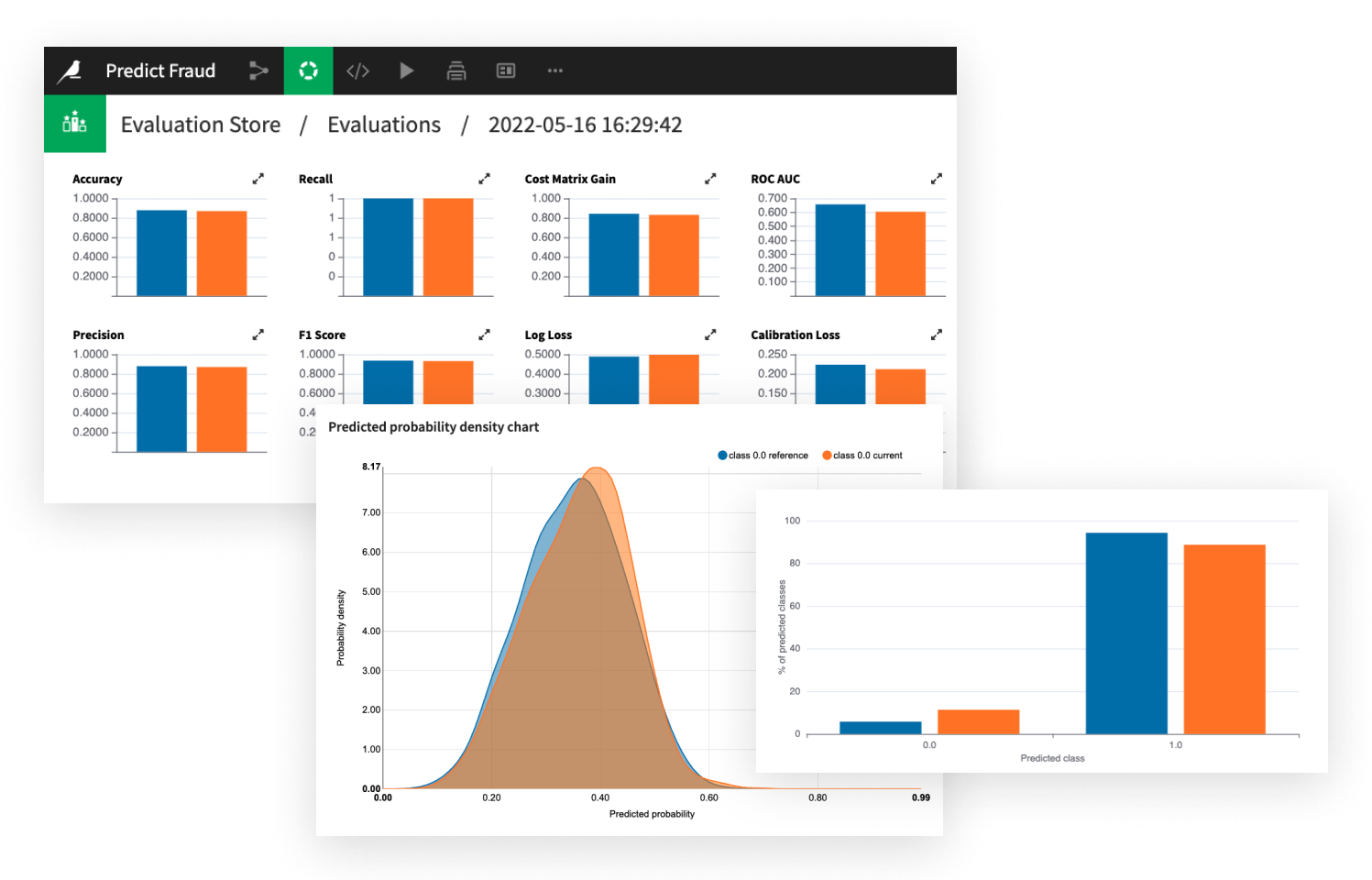
Dataikuのモデル評価ストアは、モデルの動作を時間の経過とともに視覚化するための主要なメトリックを記録します。これより、モデルがドリフトまたは劣化する時期についてインサイトを得て、事前に対応することが可能です。
これらのメトリクスを使用してドリフト検出のためのチェックリストを作成し、アラートを自動化してタイムリーなアクション (再学習など) を実行できます。モデルを正確で、ビジネスの成果に即したものに保つことができます。
Dive Into How to Manage DriftDataikuにより、あらゆるモデルのバージョンを管理し、チャンピオン/チャレンジャー比較を通じてさまざまなバージョンを簡単に評価できます。モデルの更新が意図的かつ測定可能であることを確認し、より適切な意思決定に活用できます。
パフォーマンスの問題やドリフトが発生した場合、簡単に以前のバージョンに戻すことができるため、運用環境での継続性を確保し、リスクを最小限に抑えることができます。
チャンピオン/チャレンジャーのモデル比較について読む
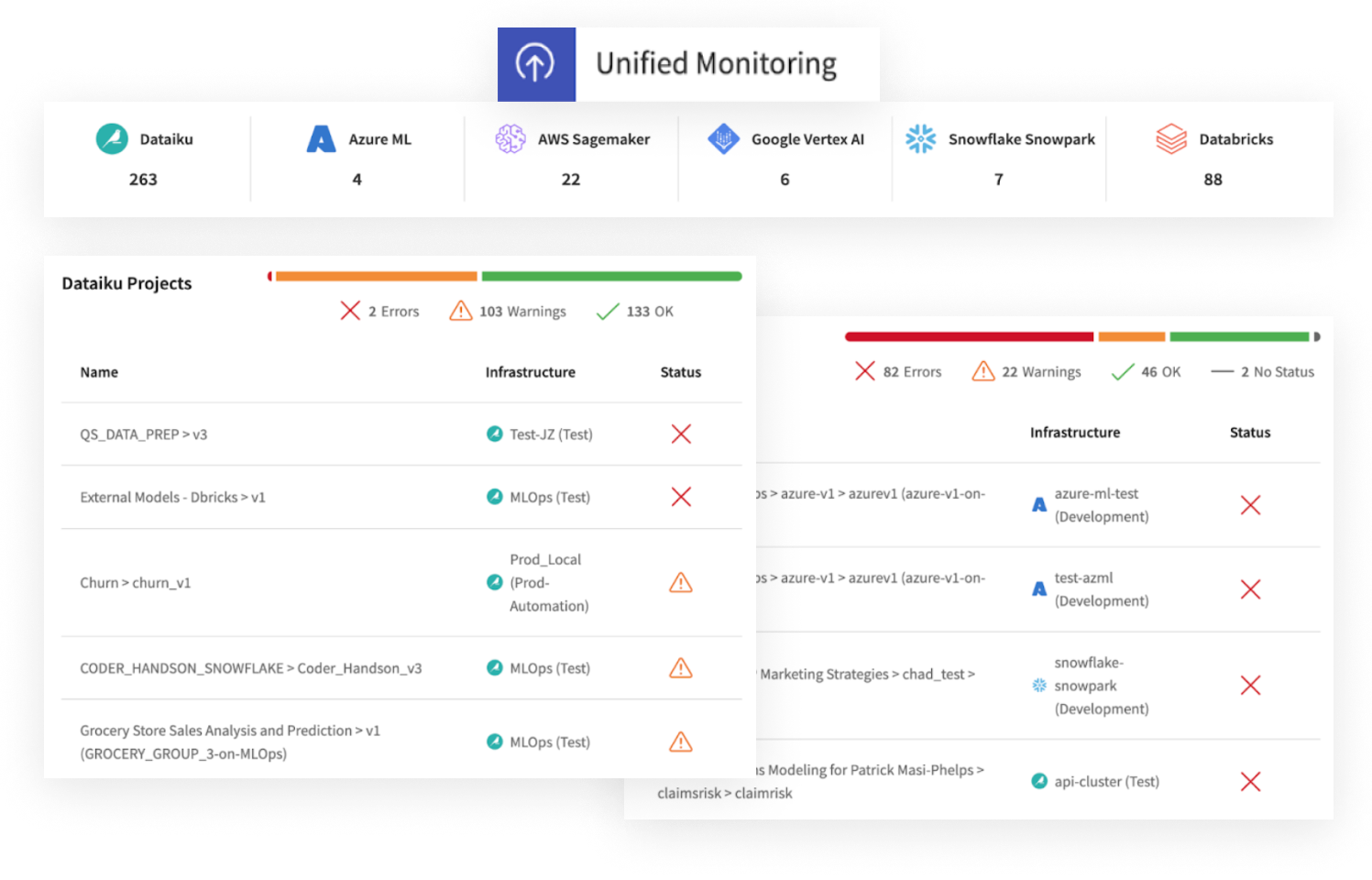
DataikuのMLOpsは、主要なプラットフォーム (AWS SageMaker、AzureML、Databricks、Google VertexAI、Snowflakeなど) とシームレスに統合します。エコシステム全体の包括的な可視化を実現し、ガバナンスや制御を犠牲にすることなく多様なプロジェクトを管理できます。
Dataikuの統合監視は、モデルの健全性とドリフトステータスの一元的なビューを提供します。インフラストラクチャーに関わらず、あらゆるデプロイに関する情報を得ることができます。
Read About Scenarios and Automation in DataikuMandMは、DataikuのデプロイインフラストラクチャーとMLOps機能を活用し、コードのみのアプローチに比べ10倍高速に運用化を実現。数百の機械学習モデルを本番稼働環境にデプロイし、監視ししています。
Dataiku導入前、Western Digitalにおける物体検出モデルの開発およびデプロイプロジェクトの一般的なリードタイムは約 1 -2四半期でした。 Dataikuを利用することで、同様のユースケースではプロセス全体にかかる時間はわずか1-2週間です。
私たちは(Dataikuを)データ前処理、プロトタイピング、製品開発に使用しますが、さらに重要なのは、使いやすいMLOpsを備えた展開プラットフォームとして、また、モデルを中心とする本番稼働インフラストラクチャーとして使用することでした。
Dataikuは、ドキュメントを自動生成し、コンプライアンスを実現可能にし、あらゆるプロジェクトを再現可能にすることで、モデルガバナンスをシンプルにします。Dataikuを使用すると、ユーザーはデプロイ前にモデルのストレステストを実施できるため、パフォーマンスを検証し、潜在的な脆弱性を特定できるようになり、信頼性の高い結果を得ることができます。
Learn More About Flow Explanation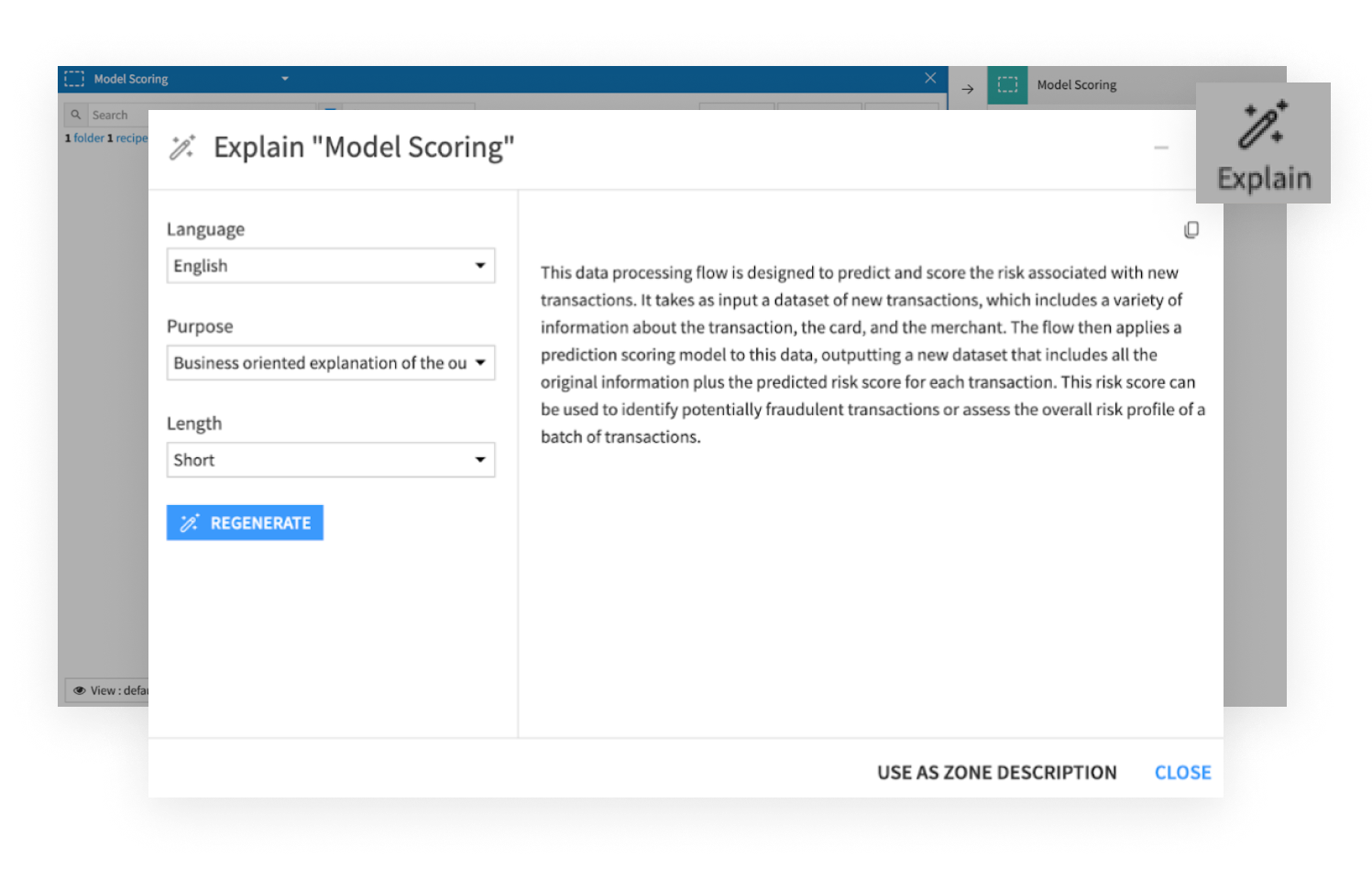

DataikuのPython APIにより、ITチームとエンジニアはDataikuタスクをプログラムで実行し、Jenkins、GitLabCI、Travis CI、Azure DevOps などのツールを使用して既存のDevOpsパイプラインに統合できます。
モデルのデプロイメントとワークフローの監視を、確立された開発プラクティスと並行して実行できるようにすることで、継続的なデリバリーを実現し、AIプロジェクトのアジリティーを維持し、ソフトウェアエンジニアリングプロセスとの整合性を提供します。
Dataikuのオプショナリティ