2023年のDataiku Everyday AI Conference のフランクフルトセッションでは、季節ごとの印刷広告キャンペーンを最適化するためのAIモデルの設計、テスト、活用について詳しく知る業界リーダーからお話を伺うことができました。Dr. Stefan Mayer, senior data scientist at Marc O’Polo , shared details about the projects that he and his team executed using uplift modeling .Marc O’Polo のシニアデータサイエンティストであるStefan Mayer博士が、アップリフトモデリング を使って実施したプロジェクトの詳細を紹介してくれました。
Marc O’Poloのデータモデリング
年ごと、季節ごとに急速に変化する可能性がある業界の一員であるMayer氏とそのチームは、データサイエンスのメリットを活用できることが不可欠であると理解しています。60か国以上に展開し、豊富な業界知識を持つ従業員が2,000人以上いるMarc O’Poloは、アップリフトモデリングを使って業務を強化し、現在のキャンペーンに効果があることを示しました。
Marc O’Poloのデータサイエンスチームは少数精鋭で、5人のデータアナリストとデータサイエンティストがいます。Mayer氏は、「Eショップと最もデータ量が多い部署のレポート分析から始めました。現在ではマーケティングとロジスティクスもサポートしており、商品チームやデザインチームとも連携するようになりました」と言います。Mayer氏によれば、Marc O’Poloのチームはもともと非常にクリエイティブな個人の集まりなので、彼らをデータに基づく考え方へと転換させるには多少の努力が必要ですが、全社でこのような基礎知識を形成することは不可欠であると確信しているということです。
→ WATCH THE FULL SESSION
Marc O’Poloでは約3年前にデータサイエンスプログラムを開始し、データサイエンスプラットフォームとしてDataikuを構築しました。
— Marc O’Polo、シニアデータサイエンティスト、Stefan Mayer博士
アップリフトモデルの必要性
季節要因の影響が大きい企業の一員として、Mayer氏はマーケティング費用を最大限に活用することの重要性を理解しています。さまざまな広告チャネルがある場合、これは特に重要なことです。「年に2回、さまざまな国でかなり大掛かりな販売キャンペーンを実施しています」とMayer氏は説明します。ソーシャルメディアを含む多様なチャネルから顧客にリーチしますが、Marc O’Poloにとって重要なメディア形態の1つが印刷物です。「当社のお客様は実店舗を利用される方が多く、価値が高く手で触れられる顧客接点として、今なお印刷物が重宝されています。しかし、ご存じのとおり、印刷物はコストが高いため、郵送すべき相手について慎重に考える必要があります」。
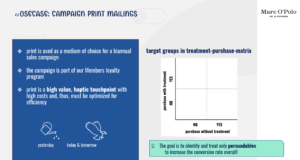
Mayer氏の説明によれば、モデリングを利用できるようになる前はシンプルな選択ルールを使っていましたが、費用対効果や効率性の面で最良ではありませんでした。「例えば、上得意客に郵便物を送るだけでは、最良の選択肢とは言えません」。そして、「誰に郵便物を送るべきかを検討する場合は、介入と購入のマトリックスが役立ちます」と付け加えました。
「横軸は、郵便物なしで購入が行われるかどうかを表しています。これをもとに、右上から始まる4種類の顧客セグメントを作成しました」とMayer氏は説明します。 Dataikuが提供するカスタマイズされたセグメンテーションソリューション では、AIと機械学習を活用して価値の高い顧客を見つけることもできます。
確実: 程度の差はあっても、最もロイヤルティの高い顧客です。Marc O’Poloは、このセグメントの顧客が郵便物を受け取るかどうかにかかわらず購入することをほぼ当てにできます。言い換えると、この顧客に郵便物を送っても購入の意思決定に影響はありません。
見込みなし: その対角のセグメントの顧客は、たとえ郵便物を送っても購入する可能性はまずありません。
あまのじゃく: Mayer氏が強調した3つ目のセグメントには、Marc O’Poloでの存在感は低いが、認識する必要がある顧客が含まれます。Mayer氏によれば、このような顧客は郵便物を受け取るとある種の警戒をします。「例えば、通信会社が契約のことを思い出させると、このセグメントのお客様は契約を更新するのではなくキャンセルしたいと考えます」。
説得可能: Mayer氏は、これを最も興味深い研究対象セグメントと呼んでいます。「郵便物を送った場合、このセグメントの顧客は購入するように説得できるので、このような顧客を特定し、その人だけに郵便物を送って、全体的なコンバージョン率を高めることが目標になります」。
説得可能顧客が持つパワー
特定の顧客セグメントをはっきりと念頭に置いて、Mayer氏とそのチームは説得可能顧客をターゲットとするためのモデルの作成を始めました。この作業は約2年前に開始されました。彼らはアップリフトモデリングアプローチを採用し、2つの別個のモデルをトレーニングしました。1つのモデルは過去に郵便物を受け取ったことがある顧客向けで、もう1つのモデルは受け取ったことがない顧客向けです。Mayer氏はこれを「両方のモデルを現時点でお客様に適用すると、2種類の購入確率が得られます。唯一の違いは、1つ目のモデルではお客様が郵便物を受け取っていたという点で、郵便物を受け取っていないお客様は2つ目のモデルの購入確率になります」と説明しています。
これら2つの購入確率の差を計算することで、アップリフトを予測できます。この値を最大化する必要があります。
— Marc O’Polo、シニアデータサイエンティスト、Stefan Mayer博士
詳細な調査とパートナーシップ
「ケルン大学 やValantic という企業と連携できる可能性があったため、さらに一歩前進したいと考えました」とMayer氏は説明しました。チームは、最新の業界調査を利用して、既存のモデルをさらに発展させたいと考えました。そこで、アップリフトモデリングの専門家と連携して、カスタムのアルゴリズムと分割基準を作成し、業界内の他社のモデルで自分たちのモデルを強化しました。いくつかのカスタム機能のエンジニアリングとモデルのトレーニング後、アップリフトモデルを最新のキャンペーンに適用できるようになったとMayer氏は述べました(これを書いている2023年夏の時点)。さらにMayer氏は、その成果や、長期にわたるトレーニングから得た教訓について説明しました。
「ほとんどの時間は、データの準備 やモデルのトレーニングに費やされました」とMayer氏。チームは2020年のキャンペーンのデータを使って、郵便物を受け取った顧客と受け取らなかった顧客を対象に、独立したA/Bテストを実施しました。これがモデルのトレーニングの基礎となりました。Mayer氏は、「質の高いデータセットに基づくデータ戦略のみを検討しました。 プロジェクトのこのフェーズでは、実際には何も変更しませんでした。アルゴリズムに標準の設定と標準のハイパーパラメーター を使っただけです」と話しました。
データ戦略からアップリフトモデリングへの移行
Mayer氏は、強力なデータ戦略の策定から生じる課題について詳細に語りました。「欠測値を扱うため、さまざまな戦略を用いました。例えば、属性の1つとして年齢がある場合、もちろん、すべての顧客の年齢がわかるわけではないので、この欠測値をどのように扱うかを検討する必要がありました。欠測値を平均値、最大値、または最小値で置き換えることも、他の複雑な戦略を利用することもできます」。
チームは、さまざまなコーディング戦略についても決定しなければなりませんでした。「外れ値を扱っていたので、さまざまな属性間の相関関係や、さまざまな機能選択戦略を検討する必要がありました」。最終的に作成したのは、属性数が約30~300、18種類のデータセットでした。 詳しくは、Dataikuが企業に合わせたカスタムアプリケーション を提供する方法をご覧ください。
データセットを設計したあとは、その使用方法を決定する必要がありました。Mayer氏は、「約17種類のアルゴリズムを用意しました。アップリフトモデリング用に構築したアルゴルズムもあれば、特定のカスタム機能を持つアルゴリズムもあります。ハイパーパラメーターの組み合わせは約2,000種類あり、すべてのモデルでアップリフトを特定することができます」と話します。
基盤となる強力なデータ戦略を見つけたあと、チームはこれらを組み合わせてデータセットを強化しました。この段階からは、微調整のトレーニングになりました。
最も質の高いデータセットと最適なハイパーパラメーターで、最良のアルゴリズムを選択することができました。
— Marc O’Polo、シニアデータサイエンティスト、Stefan Mayer博士
厳格なモデルテストと結果
チームは、直近のキャンペーンでカスタマイズしたモデルの使用を開始し、新しいモデルとこれまで使用していた構築済みのモデルを比較することにしました。「顧客ベースを5種類の無作為抽出セグメントに分割する評価設計を考案しました。コントロールグループは郵便物を何も受け取らず、介入グループではすべての顧客が受け取ります。残り3つのグループのうち、2つのグループでは構築済みのモデルを使用し、最後のグループでは新しいモデルを使用しました」。すべてのグループは互いに独立しているため、Mayer氏のチームはバイアスなしで、予測アップリストで結果を比較することができました。
「コントロールグループでは、コンバージョン率は10.8%でした。これは、このグループの顧客の10.8%が購入したということを意味します。介入グループのコンバージョン率は12%でした。これらのグループ間の重要な違いである郵便物の送付の有無によって、コンバージョン率が1.2%向上したのです」とMayer氏は明らかにしました。1つ目のモデルのコンバージョン率は10.9%だったので、アップリフトは約0.2%、アップリフト上限との相対比較では14%になります。Mayer氏によれば、新しいモデルで同様に実行されたキャンペーンのコンバージョン率も10.9%でしたが、コンバージョン率をさらに0.4%高めることができました。
0.4%のコンバージョン率増加はアップリフト上限のほぼ⅓に相当し、アップリフトモデリングではかなり良い値です。絶対的にはそれほど大きい値に思われませんが、顧客ベースの観点からは本当に大きな違いになります。
– Marc O’Polo、シニアデータサイエンティスト、Stefan Mayer博士
チームは長い時間を費やしてキャンペーン後分析を実施し、これまで使っていた最初のセグメンテーションと比較して、モデル間の違いを調べました。
実施後に学んだことと次のステップ
モデルを使って同様の分布を実現することで、チームは元のセグメンテーションの精度と信頼性を把握しようとしました。Mayer氏は、チームが構築した新旧のモデルはどちらも顧客の大部分を正しく分類していただけでなく、新しいモデルのパフォーマンスは全体として素晴らしかったと説明しました。
調査結果の中でMayer氏が注目したのは、モデルのパフォーマンスと印刷広告の費用の相関関係でした。「コンバージョン率のアップリフトを高めることができるのは間違いありませんが、新しいモデルでは『確実』セグメントでの誤差が大きくなることにも気づきました。これは大きな問題ではありません。なぜなら、ロイヤルティが高く、不満を表す可能性が低い顧客に郵便物を送っているからです。それでも、もちろん無駄遣いにはなります」。
また、アップリフト上限の最大値が実際にはやや小さいことも評価設計からわかったので、これを拡大したいと考えています。「これは今すぐに影響を与えられることではありませんが、このユースケースからわかったことです」とMayer氏は語り始めました。「結果として、経済的メリットは郵送料に左右されます。したがって、郵送料がある基準値を越えている場合は、アップリフトモデルを使用することが理にかなっています。郵送料が高すぎる場合、メリットはありません」。
次回のキャンペーン(これを書いている時点では2023年冬)では、コントロールグループと介入グループで同じ評価設計を使用し、「説得可能顧客」の数をより正確に測定することを計画しています。「説得可能顧客をターゲットにするために新しいモデルを使用するのは、間違いなくパフォーマンスが最も優れているからです。ただし、郵送料が安い国ではこのモデルを使用せず、単にすべての顧客に郵便物を送付します。そのほうが経済的にメリットがあるからです」とMayer氏。
最後に、Mayer氏はまだやるべきことがあると話しました。「このモデルを最大限に活用するための拡張を検討しています。郵便物にパーソナライズされたコンテンツを含める新しいユースケースについても検討中です」。他のマーケティングチャネルなど、実験や今後のプロジェクトに適した手段はほかにもありますが、Mayer氏はアップリフトモデリングが最も役に立つ可能性があると考えています。